基本原理
语音识别(Automatic Speech Recognition),一般简称ASR;是将声音转化为文字的过程,相当于人类的耳朵,即HMM中三大问题(概率计算,学习,预测)中的预测问题:已知观察序列求最可能的状态序列。
- HMM中状态序列是自定的状态,一般也是要求的项,比如jieba分词中的HMM状态为(BMES, begin, end , mid, single),五元组(A状态转移,B发射矩阵,π),观测序列o,状态序列s,注意是序列,即o1o2o3,转移矩阵可任意两个状态转移所以是N*N
- HMM分为离散马尔科夫和连续的马尔科夫。比如说,离散的我可以穷举出所有的观察可能值,但是连续的就有无穷多观察值,这样Observe就不能确定了。那么需要引入GMM。
- 学习问题通常最复杂只能得局部最优解且需要求预测子问题。


文本w 发音S 音素q 特征向量v
文本|发音 直观左右等价再展开多事件贝叶斯 音素 | 特征向量
文本|发音 —-> 文本 | 特征向量 —-> 文本, 音素|特征向量 —-> (贝叶斯) p(特征向量|音素)p(音素|文本)p(文本)

语音识别原理流程:“输入——编码——解码——输出”
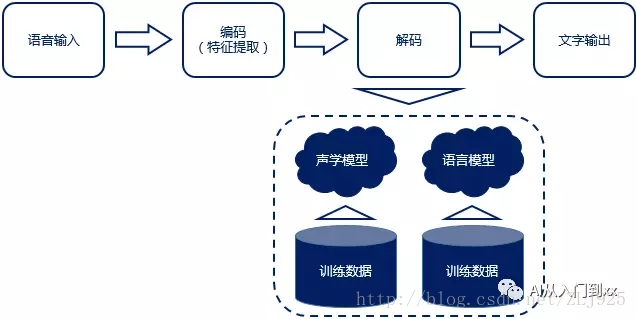
大体可分为“传统”识别方式与“端到端”识别方式,其主要差异就体现在声学模型上。
“传统”方式的声学模型一般采用隐马尔可夫模型(HMM),而“端到端”方式一般采用深度神经网络(DNN)。
声学模型

如上图所示,原始语音信号S(不稳定信号所以要交叉分帧),切割成多个短时的近似平稳信号后,经过特征提取转换成特征向量V, 声学模型就是对该特征向量的一种建模。
(1)混合声学模型–都是为了算HMM中的发射概率矩阵

混合高斯-隐马尔科夫模型 GMM-HMM详解
深度神经网络-隐马尔科夫模型 DNN-HMM
深度循环神经网络-隐马尔科夫模型 RNN-HMM
深度卷积神经网络-隐马尔科夫模型 CNN-HMM
(2)端到端的声学模型
连接时序分类-长短时记忆模型CTC-LSTM
注意力模型Attention
各个模型的优缺点介绍
(1)基于GMM-HMM的声学模型
优点:GMM训练速度快
声学模型较小,容易移植到嵌入式平台
GMM把所有的训练样本学习一遍。把类似离散马尔科夫中的发射矩阵训练出来。也就是状态->观察值(可以是数,向量等)。这样HMM再训练自己的状态转移矩阵等,这样HMM就可以用了。
缺点:GMM没有利用帧的上下文信息
GMM不能学习深层非线性特征变换
(2)基于DNN-HMM模型
优点: DNN能利用帧的上下文信息,比如前后个扩展5帧
DNN能学习深层非线性特征变换,表现优于GMM
缺点: 不能利用历史信息来辅助当前任务
(3)基于RNN-HMM模型:
优点: RNN能有效利用历史信息,将历史消息持久化
在很多任务上,RNN性能变现优于DNN
缺点: RNN随着层数的增加,会导致梯度爆炸或者梯度消失
(4)基于CNN-HMM声学模型
优点:CNN对于语音信号,采用时间延迟卷积神经网络可以很好地对信号进行描述学习
CNN比其他神经网络更能捕捉到特征的不变形


语言模型

MFCC特征提取

MFCC是在Fbank的基础上做DCT变换,去除特征维度之间的相关性,同时也可以起降维的作用,得到一般40维或13维梅尔频率,现在随着数据量的增大,这种传统机器学习逐渐被神经网络特征提取代替(CLD)。
各个组件
1)语音激活检测(voice active detection,VAD)
A)需求背景:在近场识别场景,比如使用语音输入法时,用户可以用手按着语音按键说话,结束之后松开,由于近场情况下信噪比(signal to noise ratio, SNR))比较高,信号清晰,简单算法也能做到有效可靠。
但远场识别场景下,用户不能用手接触设备,这时噪声比较大,SNR下降剧烈,必须使用VAD了。
B)定义:判断什么时候有语音什么时候没有语音(静音)。
后续的语音信号处理或是语音识别都是在VAD截取出来的有效语音片段上进行的。
3)麦克风阵列(Microphone Array)
A)需求背景:在会议室、户外、商场等各种复杂环境下,会有噪音、混响、人声干扰、回声等各种问题。特别是远场环境,要求拾音麦克风的灵敏度高,这样才能在较远的距离下获得有效的音频振幅,同时近场环境下又不能爆音(振幅超过最大量化精度)。另外,家庭环境中的墙壁反射形成的混响对语音质量也有不可忽视的影响。
B)定义:由一定数目的声学传感器(一般是麦克风)组成,用来对声场的空间特性进行采样并处理的系统。
2)语音唤醒 (voice trigger,VT)
A)需求背景:在近场识别时,用户可以点击按钮后直接说话,但是远场识别时,需要在VAD检测到人声之后,进行语音唤醒,相当于叫这个AI(机器人)的名字,引起ta的注意,比如苹果的“Hey Siri”,Google的“OK Google”,亚马逊Echo的“Alexa”等。
B)定义:可以理解为喊名字,引起听者的注意。
VT判断是唤醒(激活)词,那后续的语音就应该进行识别了;否则,不进行识别。
C)难点:语音识别,不论远场还是进场,都是在云端进行,但是语音唤醒基本是在(设备)本地进行的,要求更高——
4)全双工(Full-Duplex)
A)需求背景:在传统的语音唤醒方案中,是一次唤醒后,进行语音识别和交互,交互完成再进入待唤醒状态。但是在实际人与人的交流中,人是可以与多人对话的,而且支持被其他人插入和打断。
B)定义:
单工:a和b说话,b只能听a说
半双工:参考对讲机,A:能不能听到我说话,over;B:可以可以,over
全双工:参考打电话,A:哎,老王啊!balabala……;B:balabala……
5)纠错
A)需求背景:做了以上硬件、算法优化后,语音识别就会OK了吗?还不够。因为还会因为同音字(词)等各种异常情况,导致识别出来的文字有偏差,这时,就需要做“纠错”了。
B)用户主动纠错。
比如用户语音说“我们今天,不对,明天晚上吃啥?”,经过云端的自然语言理解过程,可以直接显示用户真正希望的结果“我们明天晚上吃啥”。
f=sig(wX+uH+bf)
i=sig(wX+uH+bi)
o=sig(wX+uH+bo)
j=tanh(wX+uH+bj)
ElemntWise
Set stream
EventRecord
j~=fw+jw
h=o*j
p(i)logP(i)-q(i)logQ(i)
m,,,,
1 |