今天刷了一些题目,查漏补缺的同时记录一下重要的知识。
似然与概率(likelihood and probability )

前者是给定联合样本值X下关于未知参数θ的函数,后者是关于x的函数。所以这里的等号= 理解为函数值形式的相等,而不是两个函数本身是同一函数(根据函数相等的定义,函数相等当且仅当定义域相等并且对应关系相等)。
概率(密度)表达给定θ下样本随机向量X=x的可能性,而似然表达了给定样本X=x下参数θ1(相对于另外的参数θ2)为真实值的可能性。我们总是对随机变量的取值谈概率,而在非贝叶斯统计的角度下,参数是一个实数而非随机变量,所以我们一般不谈一个参数的概率。
上图为严格书写方式,竖线|表示条件概率或者条件分布,分号;表示把参数隔开,因为θ在右端只当作参数理解。。
卷积
离散信号f(n),g(n)的定义如下: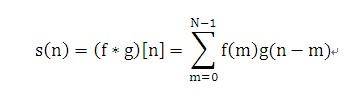
在数学里我们知道f(-x)的图像是f(x)对y轴的反转,g(-m)就是把g(m)的序列反转,g(n-m)的意义是把g(-m)平移n点。

相当于滤波器或掩码g(m)反转后在信号f(n)上平移求和。
二维卷积:


二维卷积应用(边缘检测):水平x轴与垂直y轴Sobel掩码算子: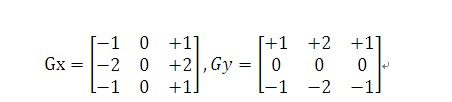
离散自相关
有了卷积的概念相关的定义跟卷积相似,离散信息f(n)的自相关用下式定义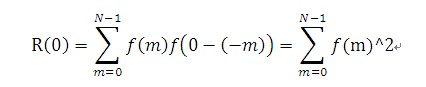
R(n) = f(n)*f(-n);
容易看出自相关函数有如下性质:
R(n)=R(-n);
n=0时,R(0)为信号的能量
精确率和召回率:
 准确率就是找得对,召回率就是找得全,漏了(1-召回率)这么多。
准确率就是找得对,召回率就是找得全,漏了(1-召回率)这么多。
正则表达式
正则表达式是一种描述性的语言, 用来概括一类字符串 (或者说一个字符串集合。
a | b* , 这个正则表达式描述了 a 和 b, bb, bbb
(a|o)(n|ff). 前面描述的是 a 或者 o, 后面描述的是 n 或者 ff, 接起来, 描述了 an, aff, on, off。
行方法
A*B=C为例,常规方法即为A行与B列对应元素相乘相加得到C中对应的元素,
即用A中每行指定的线性组合方法对B中所有行进行线性组合得到C中的每行,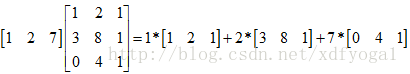
列方法(重点)
即用B中每列指定的线性组合方法对A中所有列进行组合得到C中的每列,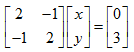
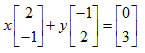
 用列的角度看待方程,这个问题即列的线性组合是否能覆盖整个空间?很明显这跟A矩阵有很大的关系,如果A是非奇异阵,这样才能组合出所有的b,以一个三方程三未知数的方程组来理解,如果系数矩阵A的3个列向量在一个平面上,那么由他们组合出的所有向量都在那个平面上,在那个平面之外的所有b都是无法得到的,这就造成方程无解。
用列的角度看待方程,这个问题即列的线性组合是否能覆盖整个空间?很明显这跟A矩阵有很大的关系,如果A是非奇异阵,这样才能组合出所有的b,以一个三方程三未知数的方程组来理解,如果系数矩阵A的3个列向量在一个平面上,那么由他们组合出的所有向量都在那个平面上,在那个平面之外的所有b都是无法得到的,这就造成方程无解。
A列B行
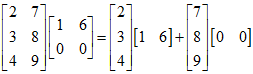
分块方法
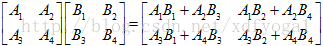
奇异值分解 - SVD
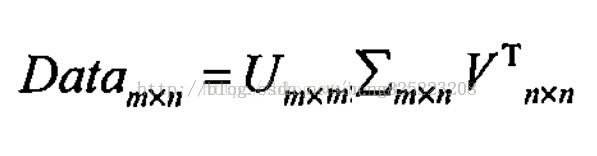 中间为奇异值矩阵,特征值的平方根,从大到小排列,小的特征越来越不重要,U为左奇异向量(ui=Avi实际上为AAT的特征向量),vi为ATA的特征向量,称为A的右奇异向量。
中间为奇异值矩阵,特征值的平方根,从大到小排列,小的特征越来越不重要,U为左奇异向量(ui=Avi实际上为AAT的特征向量),vi为ATA的特征向量,称为A的右奇异向量。
1 | import numpy as np |
奇异值分解可以将一个比较复杂的矩阵用更小更简单的几个子矩阵的相乘来表示,这些小矩阵描述的是矩阵的重要的特性。就像是描述一个人一样,给别人描述说这个人长得浓眉大眼,方脸,络腮胡,而且带个黑框的眼镜,这样寥寥的几个特征,就让别人脑海里面就有一个较为清楚的认识,实际上,人脸上的特征是有着无数种的,之所以能这么描述,是因为人天生就有着非常好的抽取重要特征的能力,让机器学会抽取重要的特征,SVD是一个重要的方法。
余弦相似度
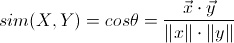
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。
1 | def cosine_similarity(vector1, vector2): |